\(E^2\) 这篇论文 Perceptual Losses for Real-Time Style Transfer and Super-Resolution 由Stanford Uni 的Justion Johnson所写, 27 Mar 2016 发表在arXiv.
名词解释
LR: 低分辨率图像 low resolutional images
HR: 高分辨率图像 high resolutional images
SR: 超分辨率图像 Super-Resolution images
CNN: 卷积神经网络 Convolutional Networks
Perceptual loss: 感知损失
VGG-16: 16 层的VGG 网络
Style Transfer: 风格转移问题
Super-Resolution: 超分辨率问题
PSNR: 峰值信噪比 — 越大说明信号损失越小
本文首先阐述了Style Transfer 和 Super Resolution 现阶段的发展。 提出了一个重要的概念–“Perceptual Loss”. 指出其他的paper用Pixel loss 来计算相似度, 也就是 \(l(sr,hr) = \frac{1}{C\times H\times W}||sr-hr||_{2}^{2}\), 这个方法把Super -Resolution 的问题理解成了一个普通的MSE 回归问题。这篇文章指出了Pixel Loss 存在的缺点,其中一个缺点为 Pixel Loss 不能判断两张图像认知上的异同。
举个例子:两张一样的图像, 只不过图像A 的所有像素都比图像B往左偏移了一个像素。 这两张图像的Pixle loss 会非常大,但这两张图像应该被判定为相同。
然而用Perceptual loss 就能很好的克服这一问题。
Perceptual loss 借用了已经训练好的VGG-16这一网络。 把VGG-16网络的中间层activations作为目标,计算两个图像经过VGG-16中间层的两个activations 的欧氏距离。 可以用如下数学公式表达:
\(\mathit{l}\_{feat}^{\phi,\text{j}}(HR,SR)=\frac{1}{C\_jH\_jW\_j}|| \phi\_j(SR)-\phi\_j(HR)||\_2^2\)
其中:
- j 是 VGG-16 的中间层代号,比如 \(j = \text{relu3_3}\) 或者 \(j = \text{Conv2_3}\)
- \( \phi_j(y) \) 指的是输入图像是y , VGG-16 网络的j 中间层的输出。比如 \(\phi_\text{relu3_3}(HR)\) 指的是HR 作为输入,relu3_3层的输出。
- \(C_jH_jW_j \) 是\( \phi_j(y) \) 的长宽高。
那么Perceptual loss 这数学公式就可以理解为两个图像在VGG-16中间层j的欧氏距离。 越小,说明VGG-16网络认为,这两张图越接近。
这篇论文又提出了一个框架来解决Style Transfer 和 Super-Resolution 问题。可以用下图来表示。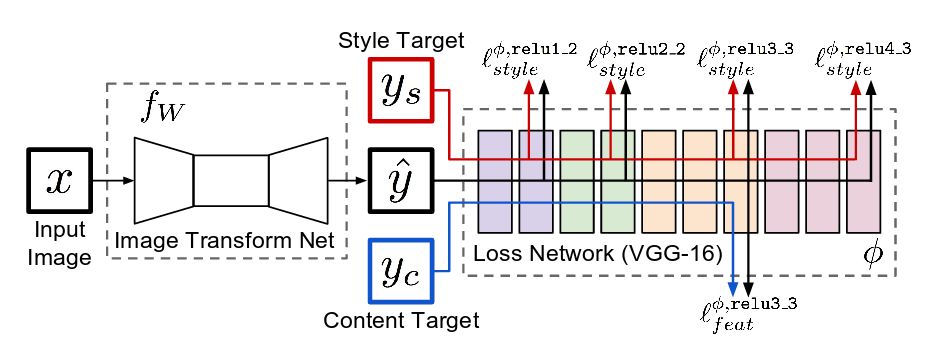
其中: 左边的fW 指的是图像变化网络,论文内使用了多层残差网络,作用是生成图像。 fW 里的weight 是我们要通过训练让网络学到的。 右边的Loss net 是用来计算Perceptual loss 的,这里使用VGG-16,而且weight 提前训练好,我们不会改变weight。更新方法为Adam。
如果用这个网络解决 Super-Resolution 问题, X是LR,\(\hat{y}\) 是Image Transform Net 以X作为输入得到的输出, \(y_c\)是原图HR。不使用 \(y_s\) (\(y_s\) 只会在style Transfer 里用到。 ) loss 为上文提到的 Perceptual loss 论文中j 使用的是relu2_2.
论文中提到的Images Transform Net 的具体细节如下:
![]()
左边扩大4倍,右边扩大8倍,
其中使用的residual network为
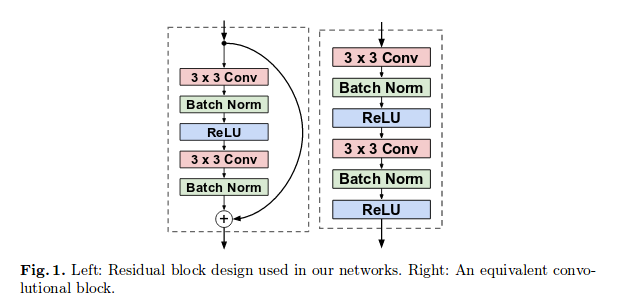
结果
