这篇论文Image Super-Resolution Using Deep Convolutional Networks
讲述了 用CNN解决了低分辨率图片转换到高分辨率图片的问题。 如果输入一张低分辨率的图片,这个神经网络能返回一张高分辨率的图片。他们把这个方法叫做SRCNN(Super-Resolution Convolutional Networks)。
名词解释
LR: 低分辨率图像 low resolutional images
HR: 高分辨率图像 high resolutional images
SR: 超分辨率图像 Super-Resolution images
CNN: 卷积神经网络 Convolutional Networks
流程
- 获取一张HR图
- 根据原图制作一张低分辨率原图,记录这个scale factor。
- 用bicubic法过采样(Upsampling )第二步获得的图像,让返回的图像和HR一样大小,但这张图仍然叫做LR。
- 训练一个三层神经网络
4.1 神经网络的输入为第三步获得的LR,输出为SR, LR和SR的size一样。
4.2 HR 作为SR 的ground truth, CNN 通过backprop 不断让SR 更逼近 HR 。 4.3 损失函数用 pixel-loss 具体公式为 \(l(sr,hr) = \frac{1}{C\times H\times W}||sr-hr||_{2}^{2}\)其中HWC 分别为图片的长,宽和color channel个数,一般为1 或3 。 这个三层神经网络可以用下图表示出来。
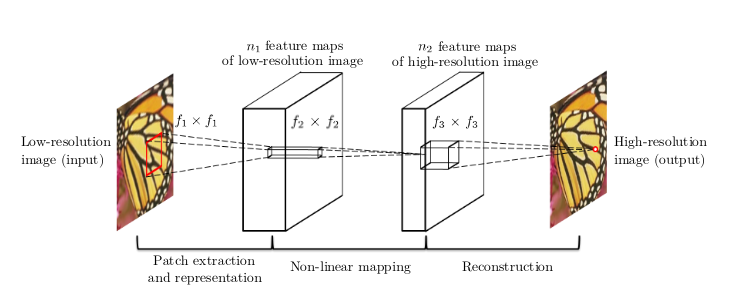
- 不断重复上述步骤, 训练这个三层神经网络,使得这个网络能获取任意大小的图像, 然后生成相应的SR
结果
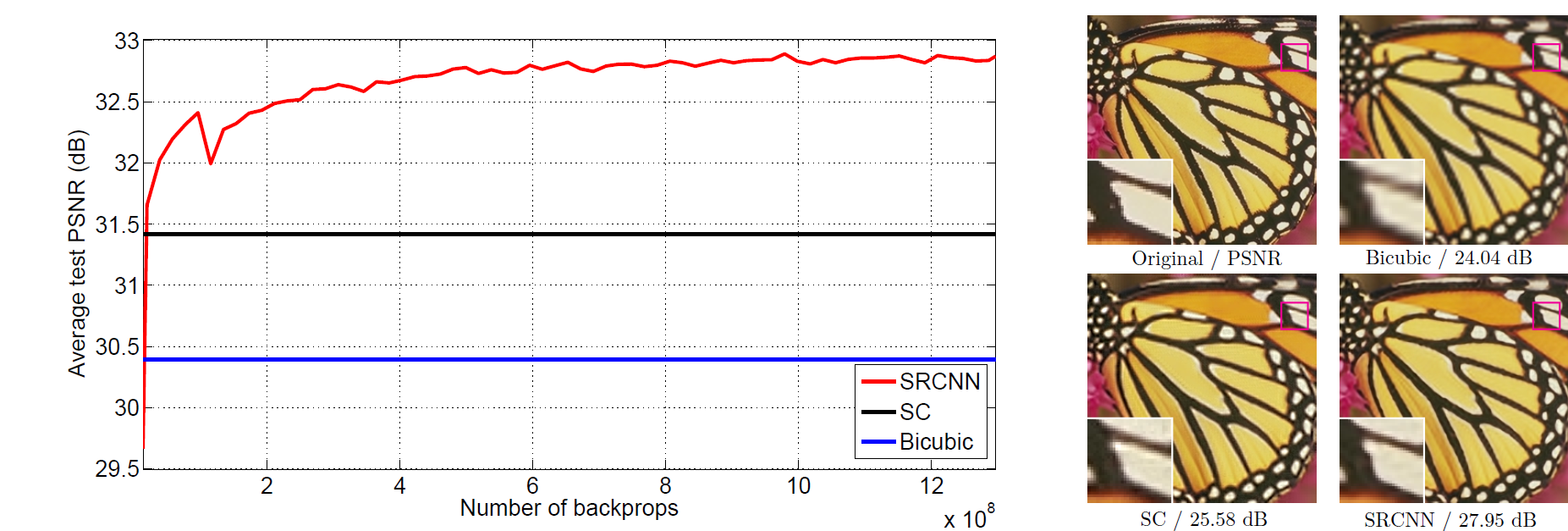
我们用PSNR 作为衡量图像一和图像二相似度的指标, PSNR 越大说明图像越相似。
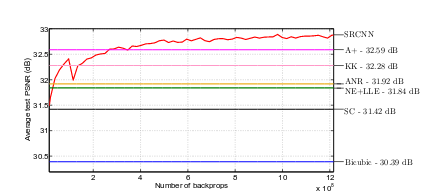
可见用SRCNN 的方法能取得比A* KK ANR 等更优的结果。
下图是他们提供的栗子

优点和缺点
文中确实证明了 SRCNN在bicubic 的基础上有进步。 但是直接在bicubic 上做,有点投机取巧。 文中提到彩色图像RBG 换成ycbcr 通道以后只在Y 通道做SRCNN 比直接在RGB 上做更好(PSNR 高了零点几)。 但我重复做了以后发现图像会饱和 , YCBCR 的图有些像素很明显出现偏差,不知原作者是怎么处理的, 好在用RGB 直接做也能做出不错的结果。