由于过拟合, 通过观看YYF的录像,YC 可能真的学不到。 –鲁迅
过拟合本是一个机器学习的概念,指的是在训练过程中引入过多参数,使测试集的错误率不降反升。
用一张图来表示过拟合。
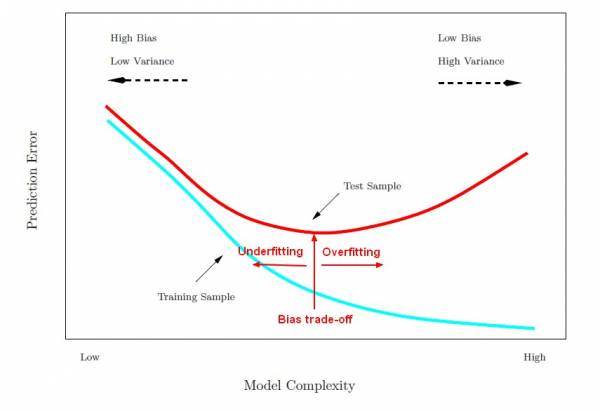 由图可见, 随着模型越来越复杂, 错误率会先变低,随后变高。 变高的部分就是过拟合的部分。 同时指的注意的是,Y轴是错误率,而不是Neural networks 的Loss。当然,在做回归(regression)的时候,这里的Y轴应该是二次平方和(sum square error)。
由图可见, 随着模型越来越复杂, 错误率会先变低,随后变高。 变高的部分就是过拟合的部分。 同时指的注意的是,Y轴是错误率,而不是Neural networks 的Loss。当然,在做回归(regression)的时候,这里的Y轴应该是二次平方和(sum square error)。
还有,在训练的时候有时候会发生训练错误率(resubstitution error) 升高的情况,这说明学习速率(learning rate) 太高了, 建议减小十倍再测试。
这里有张图,很形象得解释了什么是过拟合~
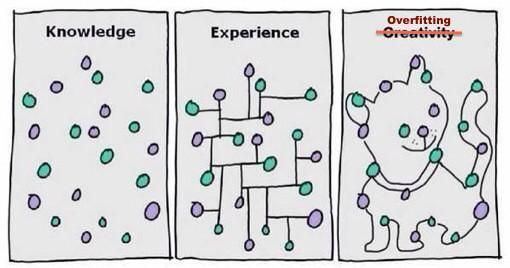
过拟合并不只是一个仅限于机器学习的概念。 过拟合还发生在生活中,我们有时候没有发现罢了。
生活经验告诉我们: 复习的时候要远离学霸和学渣。因为学霸复习一天,你得复习一星期,极度打击学习自信心。 远离学渣,因为他会勾引你出去浪。 要复习就要找天天喊着学习,但由于学习方法不对,学习成绩一直上不去的人。因为看着他努力,但成绩比你差,你会非常开心。
我翻了朋友圈,发现这么一个同学,于是约他一起复习。
我们边复习边吐槽,说这个老师太垃圾~ Lecture Slide 全是 抄隔壁UCL的 。 辣鸡老师,要报警啦,真是复习不下去啦~
欢声笑语中,我忘记了复习的痛苦。 但他没有,他依然记得那个被老师支配的下午。 突然间,他停止了吐槽。沉默半响不说话,口水从他脖子咽下去仿佛花了半个钟头。他抬起头,左手关上笔记本, 眼泪汪汪看着我,和我说: 大哥,他的课我实在是看不懂,我们来做模拟卷吧。
我自然而然的拒绝了他。 摸了摸他的头,并告诉他,翻到课件第XX 页 你看这章讲的是过拟合。 如果没复习完,就做模拟卷,就会产生过拟合。 到时候你只学会了模拟卷上的题,而不理解其他内容,无法输出知识。
他听了以后看我的眼神都变了。痛苦的眼中透露出一丝希望,但又被洪水淹没。 迟疑了几秒钟,重新打开笔记本,看起了课程录像~
学车也是一件容易过拟合的事情。 大家在考驾照的时候 教练都会在地上划线,然后告诉你左打半圈看到这三个点共线之后再把方向盘打死。 这就是过拟合, 学员到最后也只学会了如何在这个场地开车,而没学会开车这个技能。 英国的驾校考试和中国是不同的。 英国地方小,没有固定考场和训练场。学车和考试都在大马路上进行, 路上随时有突发状况(noise)考验着学员的真实实力。 英国这样的做法实际上是提高训练集数量,从而避免过拟合。
最后说到股票策略中的过拟合。 许多在线社区都提供了编写策略功能。 大家编写策略, 多多少少都会涉及到各种参数, 比如一个小盘股策略,PE多大算大? 市值设置多小算小?开仓几只股票比较合适? 调仓次数多频繁算频繁? 通常的做法是选择一个回测区间, 通过调整这些参数, 选取一个在此回测区间内表现最好的参数 ,作为最佳参数 。之后策略都运行在此参数之下。
但这恰好就是过拟合。 因为我们无法保证这些参数在回测区间之外也能表现良好。 实盘赛之前需要跑几个月的模拟盘就是增加一个验证集(validation set),来判断模型过拟合的程度。
和机器学习比赛例如Kaggle 不同, 金融市场的过拟合现象更加复杂。我在之前某个答案中提到过,中国金融数据缺失严重。政策改变对市场会造成巨大影响。 例如股指期货是在2010年诞生的,这么一个重大的影响因子应该怎么处理? 如果只在乎有股指期货的时间段,那么这段时间只有2010到2015股指期货阉割的这5年,满打满算61个月。股指期货新政出来后,先前拟合的许多参数都需要重新计算。
还有一点便是熊市和牛市。如果想要编写一个只在牛市使用的策略,对不起,你的训练集只有两次,加起来24个月。而且上一轮牛市和未来的牛市有太多的不同,必然对参数的选择有不可忽略的影响。
避免出现过拟合,有这么几个办法。
-
增加训练集(英国学车)
-
增加数据维度(学酥看录像)
-
增加验证集( 拿相似的数据测试,并问自己, 你学到了吗?)
-
改变训练方法 (改用不容易过拟合的模型,i e.随机森林)